深度学习模型中的权重初始化经常被人忽略,而事实上这是非常重要的一个步骤,模型的初始化权重的好坏关系到模型的训练成功与否,以及训练速度是否快速,效果是否更好等等,这次我们专门来看看深度学习中的权重初始化问题。本文参考斋藤康毅的书籍《深度学习入门》。
首先,一般的权重初始化是用高斯分布生成的值再乘以0.01后得到的,也就是均值为0,标准差为0.01的一组随机数。模型会使用初始化之后的权重再进行训练。
np.random.randn(10, 100)*0.01为什么权重值不能设置为全零,或者完全一样的值呢?因为在误差反向传播中,所有的权重值都会进行相同的更新,假设一个两层的神将网络,如果第一层和第二层的权重为0,那么第二层的神经元中全部输入相同的值,这意味着反向传播时,第二层的权重全部都会进行相同的更新,这样的话,权重都会更新为相同的值,也就是所有分量的权重都一样,因此损失将不会下降,也就无法进行学习了。
下面我们来看看进行不同的权重初始化后,网络激活值的变化。
假设有一个五层的神经网络,激活函数使用sigmoid函数,用直方图画出每层的激活值的数据分布:
import matplotlib.pyplot as plt
def sigmoid(x):
return 1/(1+np.exp(-x))
x = np.random.randn(1000, 100) # 1000个数据,每个数据100维
node_num = 100 # 隐藏层的节点数
hidden_layer_size = 5 # 隐藏层的数量
activations = {} #激活值的结果
for i in range(hidden_layer_size):
# i=0的时候先计算激活值,往后每次的输入值x都是上一次激活值结果
if i!=0:
x = activations[i-1]
w = np.random.randn(node_num, node_num)*1 # 权重初始化
z = np.dot(x,w)
a = sigmoid(z) # sigmoid函数
activations[i] = a# 绘制直方图
for i, a in activations.items():
plt.subplot(1, len(activations), i+1)
plt.title(str(i+1)+"-layer")
plt.hist(a.flatten(), 30, range=(0,1))
plt.show()目前我们的初始化权重是高斯分布的随机数,也就是均值为0,标准差为1,得到的结果如下图所示:
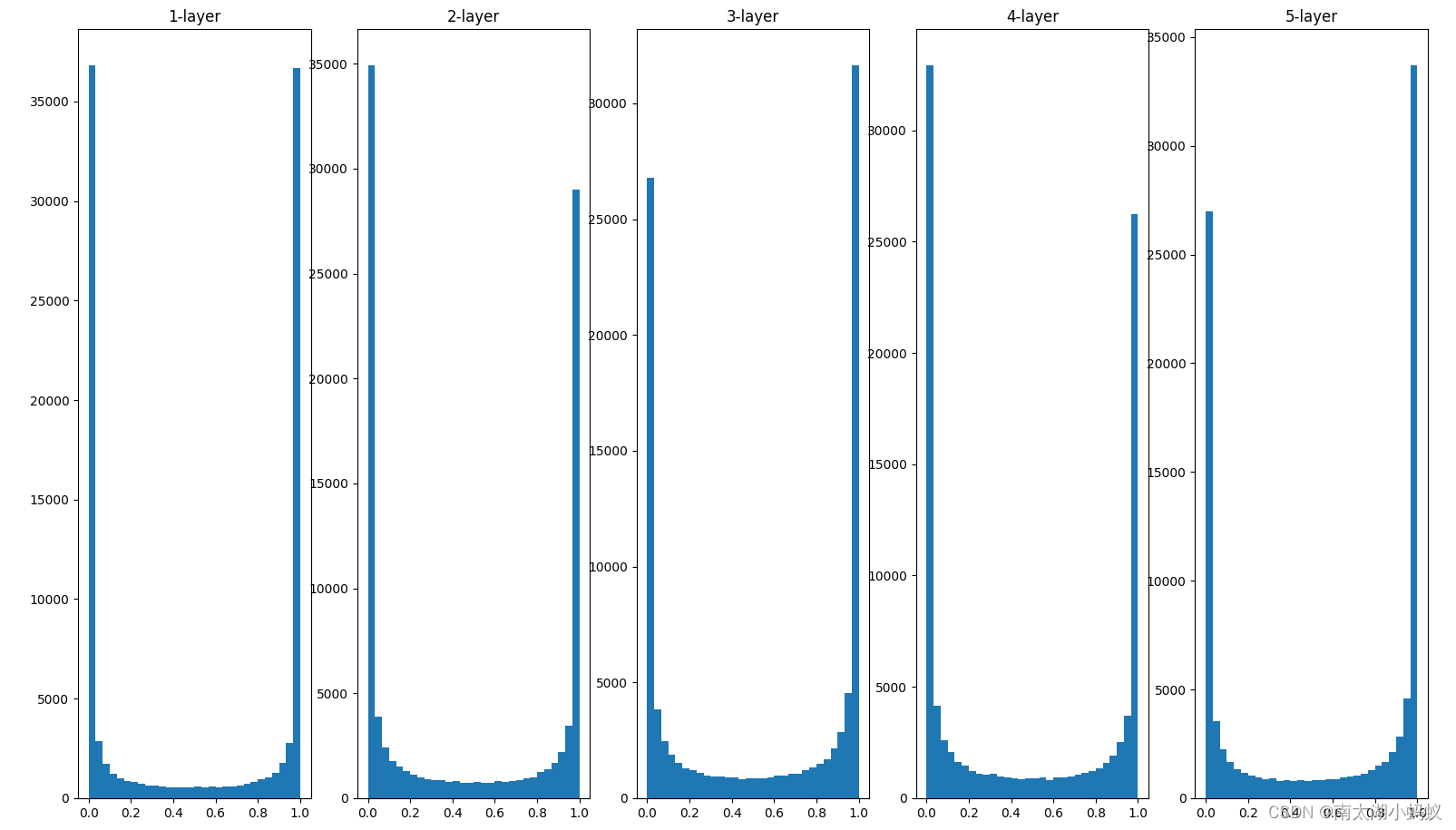
可以看到随着层数加深,越来越的多激活值集中到0和1,从而导致它们的导数接近0,因此偏向0和1的数据分布会造成反向传播中梯度值不断减小,从而产生“梯度消失”问题,特别是当神经网络的层数不断加深时,这种问题会更明显。
下面我们把初始化权重变成均值为0,标准差为0.01的高斯分布,得到的结果如下:
w = np.random.randn(node_num, node_num)*0.01 # 权重初始化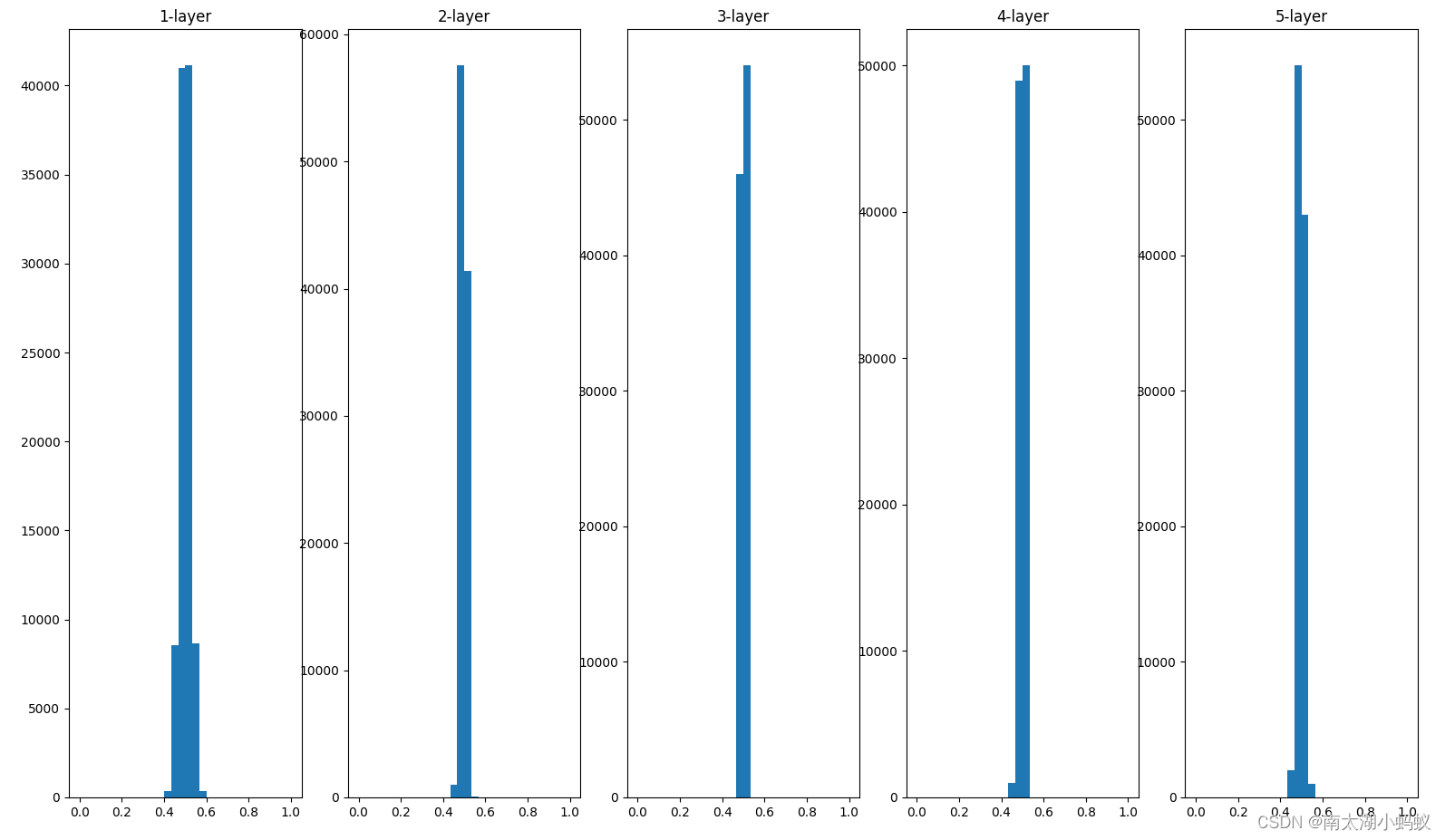
这个分布的问题是,随着神经网络层数的加深,越来越多的激活值趋于相同,如果这样下去的话,所有神经元输出的值都一样,那就是说再多的神经元效果都和一个神经元一样,因此会出现“表现力受限”问题,效果一样不好。比较理想的情况是,各层的激活值的分布都要求有适当的广度。为什么呢?因为通过在各层间传递多样性的数据,神经网络可以进行高效的学习。反过来,如果传递的是有所偏向的数据,就会出现梯度消失或者“表现力受限”的问题,导致学习可能无法顺利进行。
对于sigmoid激活值,我们采用Xavier初始值是比较理想的权重初始化方式。Xavier初始值就是,假设前一层的节点数是n,则初始权重使用均值为0,标准差为1/开根号(n)的高斯分布。
w = np.random.randn(node_num, node_num)*1/np.sqrt(n) # xavier权重初始化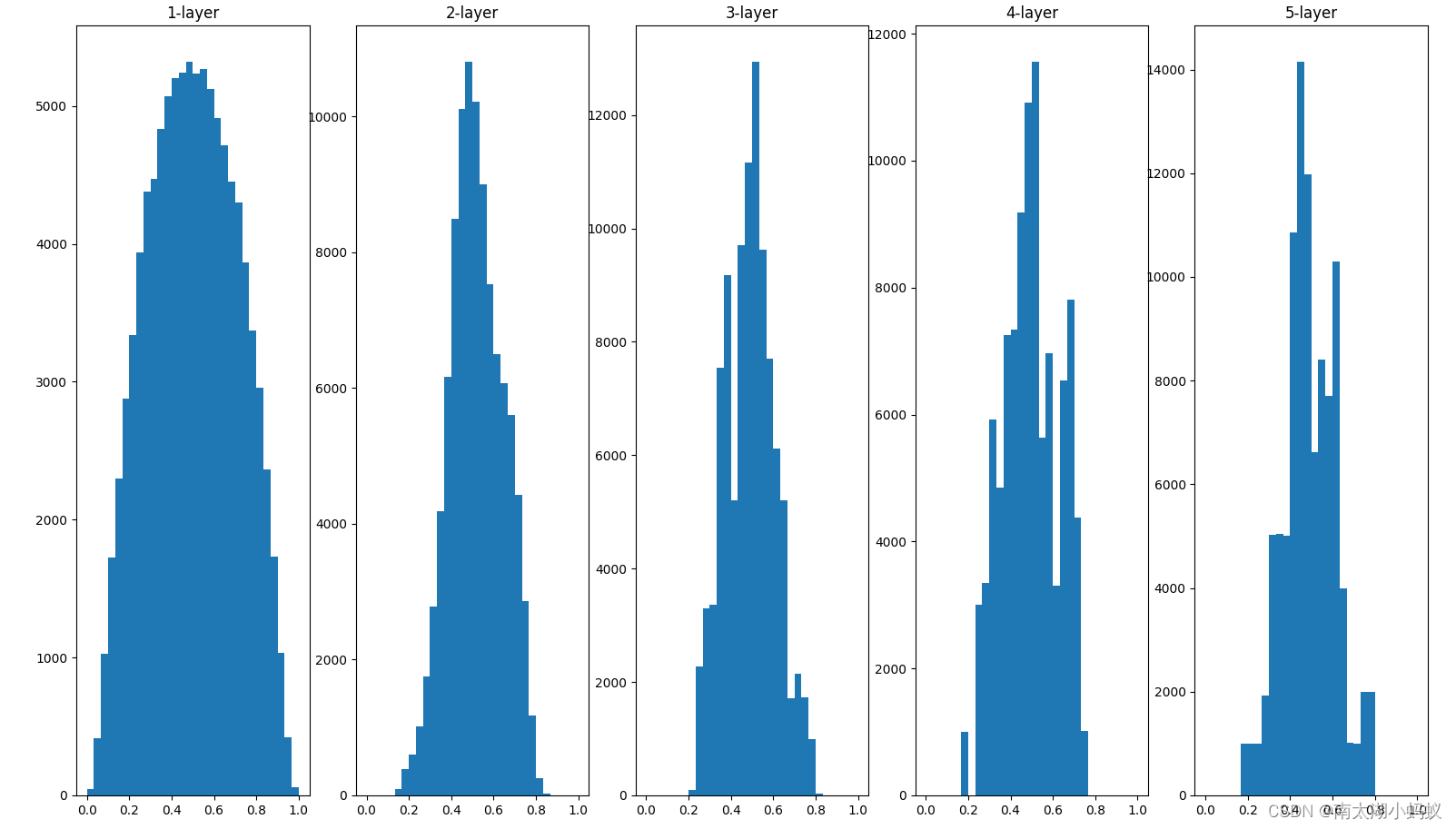
可以看到,此时输出的激活值分布具有比较高的广度,所以sigmoid的表现力不受限制,可以进行高效的学习。
不过这种Xavier权重初始化比较适合以sigmoid为激活函数的神经网络。实际应用中,我们更多的是使用ReLU作为神经网络的激活函数,当使用ReLU函数的初始化权重比较适合采用何凯明提出的kaiming权重初始化方法,kaiming初始化其实就是在xavier的基础上,根号内部乘以了2。因为ReLU函数在小于0的时候,值为0,为了增加它的广度,所以乘以了2倍系数。
w = np.random.randn(node_num, node_num)*np.sqrt(2/node_num) # kaiming权重初始化下面我们来看看这两种权重初始化的不同效果。
def relu(x):
return np.maximum(x,0)
x = np.random.randn(1000, 100) # 1000个数据,每个数据100维
node_num = 100 # 隐藏层的节点数
hidden_layer_size = 5 # 隐藏层的数量
activations = {} # 激活值的结果
for i in range(hidden_layer_size):
# i=0的时候先计算激活值,往后每次的输入值x都是上一次激活值结果
if i!=0:
x = activations[i-1]
#w = np.random.randn(node_num, node_num)*0.01 # 一般权重初始化
w = np.random.randn(node_num, node_num)/np.sqrt(node_num) # xavier权重初始化
#w = np.random.randn(node_num, node_num)*np.sqrt(2/node_num) # kaiming权重初始化
z = np.dot(x,w)
a = relu(z) # 激活函数
activations[i] = a# 绘制直方图
for i, a in activations.items():
plt.subplot(1, len(activations), i+1)
plt.title(str(i+1)+"-layer")
plt.hist(a.flatten(), 30, range=(0,1))
plt.show()
随着层数的假设,xavier权重初始化,会使得激活值越来越靠近0,从而出现梯度消失的问题。
w = np.random.randn(node_num, node_num)*np.sqrt(2/node_num) # kaiming权重初始化当我们采用kaiming初始化的时候,结果如下:
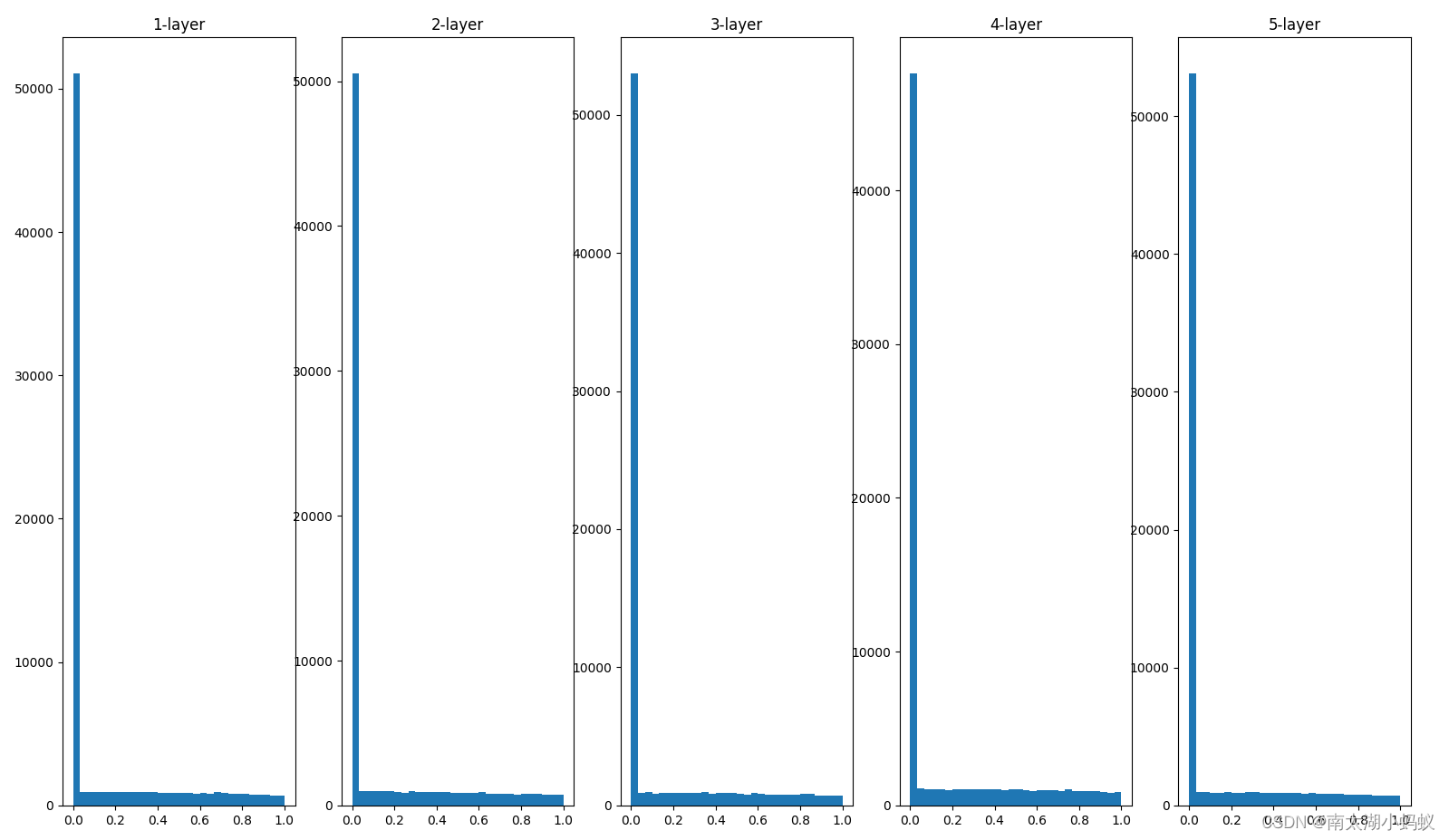
可以看到,不论层数多深,激活值总是均匀分布在0~1之间,因此适合通过反向传播进行学习。
下面我们比较一下采用(0,0.01)的高斯分布做权重初始化和用xavier做权重初始化在多层感知机上的训练效果。假设我有一个线性不可分数据集:
import numpy as np
import matplotlib.pyplot as plt
# 构建非线性可分数据集
def create_dataset():
np.random.seed(1)
m = 400 # 数据量
N = int(m/2) # 每一类数据的个数
dim = 2 # 数据维度
X = np.zeros((m,dim))
Y = np.zeros((m,1), dtype='uint8')
a = 4
# 生成数据
for j in range(2):
ix = range(N*j,N*(j+1))
t = np.linspace(j*3.12,(j+1)*3.12,N)+np.random.randn(N)*0.2
r = a*np.sin(4*t) + np.random.randn(N)*0.2
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
Y[ix] = j
X = X.T
Y = Y.T
return X,Y
X,Y = create_dataset()
X = X.T
Y = Y.T
print(Y.shape)
print(X.shape)
plt.scatter(X[:, 0], X[:, 1], c=Y, cmap=plt.cm.Paired) # 画出数据生成的图像如下,我们需要对该数据集进行分类,无法用单一的线性函数去分类,因此可以用神经网络(多层感知机)去尝试分类。
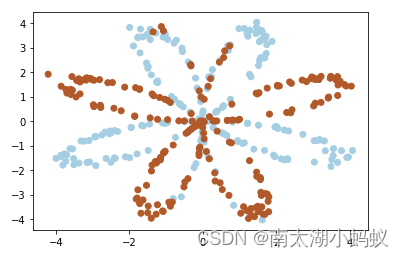
下面我们用numpy编写一个多层感知机:
def net(X,Y):
# 定义网络结构,X数据,Y标签
n = X.shape[0]
num_hidden = 4 # 隐藏层的神经元个数
m = Y.shape[0]
return (n, num_hidden, m)
def initialize_parameters(n, num_hidden, m):
# 初始化参数
w1 = np.random.randn(num_hidden, n)*0.01 # 从输入到隐藏层权重,随机初始化
#w1 = np.zeros((num_hidden, n))
#w1 = np.random.randn(num_hidden, n)/np.sqrt(n) # xavier权重初始化
b1 = np.zeros((num_hidden, 1)) # 从输入到隐藏层偏置,初始化为零
w2 = np.random.randn(m, num_hidden)*0.01 # 从隐藏层到输出层权重,随机初始化
#w2 = np.zeros((m, num_hidden))
#w2 = np.random.randn(m, num_hidden)/np.sqrt(num_hidden) # xavier权重初始化
b2 = np.zeros((m, 1)) # 从隐藏层到输出层权重,初始化为零
parameters = {'w1':w1,'w2':w2,'b1':b1,'b2':b2}
return parameters
def sigmoid(x): # sigmoid激活函数
s = 1 / (1 + np.exp(-x))
return s
def forward(X,parameters): # 前向运算
w1 = parameters['w1']
b1 = parameters['b1']
w2 = parameters['w2']
b2 = parameters['b2']
z1 = np.dot(w1,X)+b1
#print("z1.shape:",z1.shape)
a1 = np.tanh(z1)
z2 = np.dot(w2,a1)+b2
#print("z2.shape:",z2.shape)
a2 = sigmoid(z2)
cache = {'z1':z1,'a1':a1,'z2':z2,'a2':a2}
return cache
def backward_propagation(parameters, cache, X, Y): # 反向传播
m = X.shape[1]
w1 = parameters['w1']
w2 = parameters['w2']
b1 = parameters['b1']
b2 = parameters['b2']
a1 = cache['a1']
a2 = cache['a2']
# 反向传播,根据吴恩达教程的公式推导
dz2 = a2-Y
dw2 = 1/m*np.dot(dz2,a1.T)
db2 = 1/m*np.sum(dz2, axis=1, keepdims=True)
dz1 = np.dot(w2.T,dz2)*(a1-np.power(a1,2))
dw1 = 1/m*np.dot(dz1,X.T)
db1 = 1/m*np.sum(dz1, axis=1, keepdims=True)
grads = {'dw1':dw1,'db1':db1,'dw2':dw2,'db2':db2}
return grads
def loss(z2,Y): # 损失值计算
m = Y.shape[1] # 列向量的数量
loss = np.log(z2)*Y + np.log(1-z2)*(1-Y)
loss = -1/m * np.sum(loss)
loss = np.squeeze(loss)
return loss
def update_weights(parameters, grads, lr): # 权重更新
w1 = parameters['w1']
w2 = parameters['w2']
b1 = parameters['b1']
b2 = parameters['b2']
dw1 = grads['dw1']
dw2 = grads['dw2']
db1 = grads['db1']
db2 = grads['db2']
# 参数更新
w1 -= lr*dw1
b1 -= lr*db1
w2 -= lr*dw2
b2 -= lr*db2
parameters = {'w1':w1,'w2':w2,'b1':b1,'b2':b2}
return parameters
def train(X, Y):
x,n_h,y = net(X,Y) # 构建网络并获取到输入和输出节点数
print("x:{},n_h:{},y:{}".format(x,n_h,y))
parameters = initialize_parameters(x,n_h,y)
w1 = parameters['w1']
b1 = parameters['b1']
w2 = parameters['w2']
b2 = parameters['b2']
for i in range(100000):
cache = forward(X, parameters)
a2 = cache['a2']
cost = loss(a2,Y)
grads = backward_propagation(parameters, cache, X, Y)
parameters = update_weights(parameters, grads, lr=0.001)
if i%10000==0:
print("================",cost)
return parameters
X,Y = create_dataset()
parameters = train(X, Y)
print("w1:{},b1:{},w2:{},b2:{}".format(parameters['w1'],parameters['b1'],parameters['w2'],parameters['b2']))当我们使用(0,0.01)的高斯分布做权重初始化后,训练损失值如下:
================ 0.6931125167719424
================ 0.6929599436150587
================ 0.6928419798609118
================ 0.6927533221282552
================ 0.6926665006259728
================ 0.6925442899224475
================ 0.6923418054740101
================ 0.6919987185837877
================ 0.6914315483776486
================ 0.6905487939721282可以看到损失值几乎不下降,无法训练,如果使用xavier权重初始化后,训练损失值如下:
================ 0.7088135432785352
================ 0.6196813019938332
================ 0.5770935283638372
================ 0.5129738885023197
================ 0.46283119618617713
================ 0.4218237851915789
================ 0.3914602876997484
================ 0.3705175596789437
================ 0.354306018670427
================ 0.3409172900251636可以看到,使用(0,0.01)的高斯分布做权重初始化训练很难进行下去,而使用xavier做权重初始化后,训练会非常快速,损失值平稳的下降。最终分类结果也比较不错:
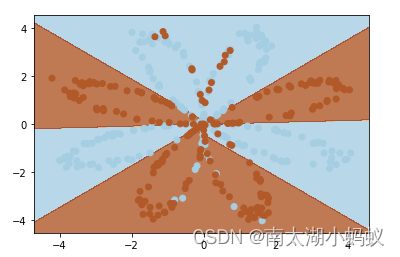
其实,我们平时工作中倒是不用特别担心这一点,因为我们现在一般采用pytorch之类的深度学习框架进行代码编写,很少从头开始构建深度学习模型,pytorch之类的框架中会对权重一个默认的初始化,而且效果都不错。不过权重初始化依然是一个非常重要的概念,对于一些特殊的模型,可能需要我们自己手动做权重初始化才能更好的训练。











![[C语言]典型例题:小蚂蚁爬橡皮筋、买汽水问题、导致单词块、菱形打印……](https://img-blog.csdnimg.cn/direct/559c20ed0664420cbe8d06083f39d0a0.png)